💡 How it started
The project started as an idea to help people identify fake news and misinformation. The goal was to create a tool that can help people verify the authenticity of news articles and other information they come across online.
The project was inspired by the rise of fake news and misinformation online, and the need for a tool that can help people separate fact from fiction especially in the age of social media and the internet.
Detection of fake news in Romanian language is a challenging task due to the lack of resources and tools available for this language. My goal was to create a tool that can help people identify fake news and misinformation in Romanian language, and to provide a way for people to verify the authenticity of news articles and other information they come across online.
🔍 Data gathering
The first step in creating the fake news detection tool was to find a dataset of fake news articles in Romanian language. I searched online for datasets of fake news articles in the Romanian language, but I couldn't find any suitable dataset that I could use for training the model. I further searched and found a dataset called FakeRom
The FakeRom dataset contains 838 fake and real news articles in Romanian language, and it was created by scraping articles from various websites and social media platforms. The majority of the articles in the dataset are real news articles, and only a small percentage of them are fake news split in nuance, satire, propaganda, misinformation, etc.
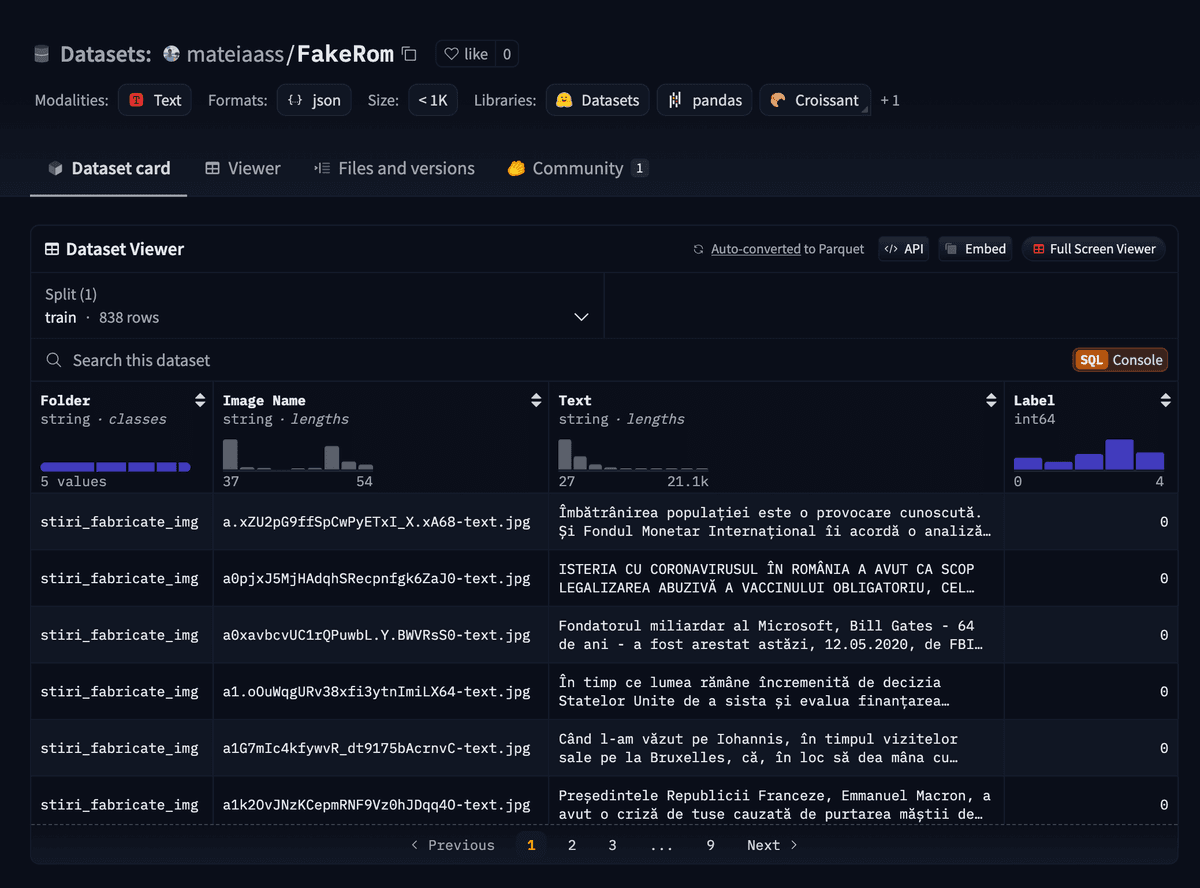
Issues with the dataset:
- The dataset contains a small number of fake news articles compared to the real news articles.
- News articles might be outdated.
- Contains articles from various sources and domains, which might affect the performance of the model.
I start think about a solution to improve the dataset by gathering more relevant and up-to-date articles. I came across a platform called Veridica that provides a list of analyzed articles and their nuance by real journalists. My toughs were: "I found the honeypot!"
The next step was to scrape the articles from the website and create a new dataset that contains real news articles and their nuance. I put together a scraper using BeautifulSoup and requests libraries in Python.
Scrapper code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
import requests
from bs4 import BeautifulSoup
import json
import concurrent.futures
def save_to_json(data, filename):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
def get_article_metadata(article):
metadata = {}
row_element = article.find('div', class_='row')
if row_element:
date_elements = row_element.find_all('time')
if len(date_elements) > 0:
# Get the first date element
date_element = date_elements[0]
# Extract the date from the datetime attribute
date = date_element['datetime']
metadata["publish_date"] = date
return metadata
def scrape_news_content(article):
# Find the div with class 'article-content'
article_content = article.find('div', class_='article-content')
if article_content:
# Find the first paragraph within the article content
first_paragraph = article_content.find('p')
if first_paragraph:
# Extract the text from the first paragraph
content = first_paragraph.get_text().strip()
return content
return ""
def scrape_news_detail(article_url):
try:
page = requests.get(article_url)
article = BeautifulSoup(page.content, 'html.parser')
title = article.find('h1').get_text().strip()
tag = "Real News"
content = scrape_news_content(article)
metadata = get_article_metadata(article)
article_data = {
"title": title,
"content": content,
"tag": tag,
**metadata,
}
print(f"Scraped article----->: {title}")
return article_data
except Exception as e:
print(f"Error scraping {article_url}: {e}")
return None
def scrape_news(url, number_of_pages, filename):
articles_urls = []
for i in range(1, number_of_pages+1):
page = requests.get(f'{url}?page={i}')
soup = BeautifulSoup(page.content, 'html.parser')
articles = soup.find_all('h2', class_='article-title-link2')
for article in articles:
article_url = article.find('a')['href']
articles_urls.append(article_url)
scraped_count = 0
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(scrape_news_detail, articles_urls, )
# Write data to file after processing each page
with open(filename, 'a', encoding='utf-8') as f:
for result in results:
if result:
json.dump(result, f, ensure_ascii=False)
f.write(',\n')
scraped_count += 1
print(f"\nTotal articles scraped: {scraped_count}");
def main():
# url = input("Enter the URL of the website: ")
url = 'https://www.veridica.ro/stiri/romania'
number_of_pages = int(input("Enter the number of pages: "))
filename = input("Enter the filename to save the JSON data: ") + ".json"
# Create an empty file to store the data
open(filename, 'w').close()
scrape_news(url, number_of_pages, filename)
print("\nScraping completed. Data saved to", filename)
if __name__ == "__main__":
main()
The scraper was able to bring 1356 articles from the website, and I used the articles to create a new dataset that contains real news articles and fake news in their nuance. This dataset will be used to train the fake news detection model and improve its performance. So far the dataset combined with FakeRom , now has 2194 articles in total. The next step is to optimize the dataset by removing special characters, stopwords, and other irrelevant information. Also to overcome the imbalance of the classes, I will use techniques like oversampling, undersampling, and SMOTE.
🧹 Data preprocessing
The next step in building the fake news detection tool involves data preprocessing to ensure the data is clean, consistent, and ready for model training. This step includes various tasks such as text cleaning, data augmentation, and handling class imbalances to optimize model performance.
Data preprocessing is critical to improving the model's performance by eliminating noise and irrelevant information, thus enhancing the model's ability to generalize. Moreover, it ensures balanced class distributions, crucial for preventing model bias.
The following steps outline the preprocessing procedure:
- Text is converted to lowercase.
- Special characters and single characters are removed.
- Multiple spaces are replaced with a single space.
The preprocessing process also includes the following advanced techniques:
- Loading JSON Data: The dataset is loaded from a JSON file using the
load_jsonfunction. - Basic Text Preprocessing: The text is cleaned by converting it to lowercase, removing special characters, eliminating single characters, and condensing multiple spaces into one using the
preprocess_textfunction. - Synonym Replacement: The minority class data is augmented using the
synonym_replacementfunction, which employs pre-trained fastText embeddings to replace words with their synonyms, enhancing the dataset’s variety. - Data Augmentation: The minority class data is further augmented by generating new samples with synonym replacement and combining them with the original data.
- Handling Class Imbalance: The RandomOverSampler method from the
imblearnlibrary is used to balance the dataset by oversampling the minority classes, ensuring that each class has an equal number of samples. - Saving the Enhanced Dataset: The processed and balanced dataset is saved in JSON format using the
save_to_jsonfunction.
The final balanced dataset is now ready for training and is saved to the specified path. Additionally, the class distribution is printed to confirm that the classes are balanced.
Data preprocessing code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
import pandas as pd
import json
import regex as re
from tqdm import tqdm
import numpy as np
from gensim.models import KeyedVectors
from imblearn.over_sampling import RandomOverSampler
import random
# Set random seed for reproducibility
random.seed(42)
np.random.seed(42)
# Function to load data from JSON file
def load_json(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
return data
# Load the data
data = load_json('../../datasets/combined_data.json')
df = pd.DataFrame(data)
# Improved preprocessing function
def preprocess_text(text):
text = text.lower()
text = re.sub(r'[^p{L}s]', ' ', text)
text = re.sub(r's+p{L}s+', ' ', text)
text = re.sub(r's+', ' ', text)
return text.strip()
# Apply preprocessing
df['content'] = df['content'].apply(preprocess_text)
# Load pre-trained fastText embeddings for Romanian
# Download from: https://fasttext.cc/docs/en/crawl-vectors.html
def load_embeddings(file_path):
print("Loading embeddings...")
embeddings = KeyedVectors.load_word2vec_format(file_path, binary=False, limit=1000000) # Limit to 1 million words to save memory
print("Embeddings loaded.")
return embeddings
# Provide the path to your downloaded fastText embeddings file
embeddings = load_embeddings('cc.ro.300.vec')
# Synonym replacement function using fastText embeddings
def synonym_replacement(text, embeddings, num_replacements=2):
words = text.split()
new_words = words.copy()
random_word_list = list(set(words))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = []
try:
# Check if the word is in the embeddings
if random_word in embeddings:
# Get the most similar words (synonyms)
similar_words = embeddings.most_similar(random_word, topn=10)
synonyms = [word for word, similarity in similar_words if word != random_word]
if synonyms:
# Choose a random synonym
synonym = random.choice(synonyms)
# Replace the word with the synonym
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= num_replacements:
break
except KeyError:
continue
augmented_text = ' '.join(new_words)
return augmented_text
# Function to augment data
def augment_data(df, label, augmentations_per_sample):
augmented_texts = []
subset = df[df['tag'] == label]
for text in tqdm(subset['content'], desc=f'Augmenting {label}'):
for _ in range(augmentations_per_sample):
augmented_text = synonym_replacement(text, embeddings)
augmented_texts.append({'content': augmented_text, 'tag': label})
return pd.DataFrame(augmented_texts)
# Calculate class counts
class_counts = df['tag'].value_counts()
print("Initial class distribution:")
print(class_counts)
# Find the maximum class count
max_count = class_counts.max()
# Augment minority classes
augmented_dfs = []
for label, count in class_counts.items():
if count < max_count:
augmentations_per_sample = max(1, (max_count - count) // count)
print(f"Augmenting class '{label}' with {augmentations_per_sample} augmentations per sample.")
augmented_df = augment_data(df, label, augmentations_per_sample)
augmented_dfs.append(augmented_df)
else:
print(f"Class '{label}' is already the majority class.")
# Combine augmented data back into the original dataframe
df_augmented = pd.concat([df] + augmented_dfs, ignore_index=True)
# Recalculate class counts after augmentation
class_counts_augmented = df_augmented['tag'].value_counts()
print("Class distribution after augmentation:")
print(class_counts_augmented)
# Balance the dataset using RandomOverSampler
ros = RandomOverSampler(random_state=42)
X = df_augmented['content'].values.reshape(-1, 1)
y = df_augmented['tag']
X_resampled, y_resampled = ros.fit_resample(X, y)
df_balanced = pd.DataFrame({'content': X_resampled.flatten(), 'tag': y_resampled})
# Verify balanced classes
print("Final class distribution after balancing:")
print(df_balanced['tag'].value_counts())
# Save the balanced dataset
def save_to_json(df, file_path):
df.to_json(file_path, orient='records', lines=True, force_ascii=False)
enhanced_dataset_path = '../../datasets/post_processed/combined_balanced.json'
save_to_json(df_balanced, enhanced_dataset_path)
print(f"Enhanced dataset saved to {enhanced_dataset_path}")
🧠 Training the model
The next step in creating the fake news detection tool is to train the model using the preprocessed data. This involves feeding the cleaned and balanced dataset into a machine learning algorithm to learn the patterns and features that distinguish fake news from real news articles.
For this project, we chose to use the BERT (Bidirectional Encoder Representations from Transformers) model, a state-of-the-art natural language processing model. BERT is particularly well-suited for this task due to its ability to understand the context of words in a sentence, making it highly effective at distinguishing between nuanced differences in text.
The training process involves fine-tuning the BERT base uncased model on our preprocessed dataset. This allows the model to learn the specific features and patterns that are indicative of fake news in the Romanian language. The model is then evaluated on a test set to measure its performance using metrics such as accuracy, precision, recall,and F1 score.
After training, the model can be used to predict whether a news article is real, or fake, and if is fake to predict its nuance. The model can also be used to generate a confidence score for each prediction based on the features it has learned. This makes it a powerful tool for verifying the authenticity of news articles and other information online.
You can read more about the BERT model and its capabilities here.
Training the model code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
from transformers import BertTokenizerFast
import torch
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import pandas as pd
from torch.nn.functional import softmax
import numpy as np
import json
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, log_loss, roc_auc_score, roc_curve, auc, confusion_matrix
def load_json(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
return data
# Sample dataset
data = load_json('../datasets/combined_data.json')
# Convert to DataFrame
df = pd.DataFrame(data)
# Splitting data
X = df['content']
y = df['tag']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Load the BERT tokenizer
tokenizer = BertTokenizerFast.from_pretrained('bert-base-multilingual-cased')
label_encoder = LabelEncoder()
# Tokenize the dataset
def tokenize_function(texts):
return tokenizer(texts, padding=True, truncation=True, max_length=128, return_tensors='pt')
train_encodings = tokenize_function(X_train.tolist())
test_encodings = tokenize_function(X_test.tolist())
class FakeNewsDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: val[idx] for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx], dtype=torch.long) # Ensure labels are long type for classification
return item
def __len__(self):
return len(self.labels)
# Fit and transform the labels
y_train_encoded = label_encoder.fit_transform(y_train)
y_test_encoded = label_encoder.transform(y_test)
# Create the datasets
train_dataset = FakeNewsDataset(train_encodings, y_train_encoded)
test_dataset = FakeNewsDataset(test_encodings, y_test_encoded)
# # Save label mapping
label_mapping = list(label_encoder.classes_)
# with open('../results/label_mapping.json', 'w') as f:
# json.dump(label_mapping, f)
# Load BERT model for sequence classification
model = BertForSequenceClassification.from_pretrained('bert-base-multilingual-cased', num_labels=len(np.unique(y)))
# Check if MPS (Metal Performance Shaders) backend is available
if torch.backends.mps.is_available():
device = torch.device("mps")
print("Using MPS backend for PyTorch")
else:
device = torch.device("cpu")
print("Using CPU backend for PyTorch")
# Set the device
model.to(device)
training_args = TrainingArguments(
output_dir='../results',
num_train_epochs=5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
evaluation_strategy="steps",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset
)
# Train the model
trainer.train()
# save the trained model
# model.save_pretrained('../build/bert_model')
# tokenizer.save_pretrained('../build/bert_tokenizer')
# Metrics storage
results = []
# Predict on the test set
# Predict on the test set
predictions = trainer.predict(test_dataset)
# Get raw model predictions (logits)
logits = predictions.predictions
# Convert logits to probabilities
probabilities = softmax(torch.tensor(logits), dim=-1).numpy()
# Decode the predictions to class labels
preds = np.argmax(probabilities, axis=-1)
# Decode numeric predictions back to string labels
preds_decoded = label_encoder.inverse_transform(preds)
# Calculate metrics
acc = accuracy_score(y_test, preds_decoded)
prec = precision_score(y_test, preds_decoded, average='weighted')
rec = recall_score(y_test, preds_decoded, average='weighted')
f1 = f1_score(y_test, preds_decoded, average='weighted')
logloss = log_loss(y_test_encoded, probabilities)
conf_matrix = confusion_matrix(y_test, preds_decoded)
# If you are using roc_curve or auc, you need to pass the correct inputs
# If you are using roc_curve or auc, you need to pass the correct inputs
fpr, tpr, _ = roc_curve((y_test == 'fake_news').astype(int), probabilities[:, 1])
roc_auc = auc(fpr, tpr)
roc_auc_per_class = {}
for i, cls in enumerate(label_mapping):
fpr, tpr, _ = roc_curve((y_test == cls).astype(int), probabilities[:, i])
roc_auc_per_class[cls] = auc(fpr, tpr)
# Specify multi_class parameter for roc_auc_score
roc_auc_micro = roc_auc_score(y_test_encoded, probabilities, average='micro', multi_class='ovr')
roc_auc_macro = roc_auc_score(y_test_encoded, probabilities, average='macro', multi_class='ovr')
# Store the results
results.append({
'Model': 'BERT',
'Accuracy': acc,
'Precision': prec,
'Recall': rec,
'F1 Score': f1,
'Log Loss': logloss,
'ROC AUC Per Class': roc_auc_per_class,
'ROC AUC Micro': roc_auc_micro,
'ROC AUC Macro': roc_auc_macro,
'Confusion Matrix': conf_matrix,
})
# Save results to json file but make sure to convert numpy arrays to lists and then save
with open('../results/results_mine_bert.json', 'w') as file:
json.dump(results, file, default=lambda x: x.tolist())
#python -m convert --quantize --task sequence-classification --tokenizer_id ./bert_tokenizer --model_id ./bert_modelWe didn"t choose to use BERT without a reason. We chose it because it is a powerful model that can be used for a wide range of natural language processing tasks, including text classification, question answering, and named entity recognition.BERT is particularly well-suited for this task due to its ability to understand the context of words in a sentence, making it highly effective at distinguishing between nuanced differences in text. We also compared it with other models like Logistic Regression (LR), Naive Bayes, and Support Vector Machine (SVM), and BERT outperformed them in terms of accuracy, precision, recall, and F1 score. Those metrics are available in the model evaluation section.
📊 Model evaluation
The model was evaluated on a test set to measure its performance using metrics such as accuracy, precision, recall, and F1 score. The evaluation results are as follows:
The model performed well on the test set, achieving high scores in all metrics. The high scores indicate that the model is effective at distinguishing between fake news nuance in articles in the Romanian language.
Bellow is a comparison between the models used in the project and their performance, trained on the original dataset and the enhanced dataset:
ACCURACY
Accuracy is the ratio of correctly predicted observations to the total observations. It is a measure of the overall performance of the model.
Formula:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
ACCURACY - FakeRom Dataset
| Model | Value |
|---|---|
| Naive Bayes Test data from: FakeRom | 84.00% |
| Naive Bayes Test data from: NEW | 31.10% |
| Naive Bayes Test data from: FakeRom and NEW | 32.20% |
| Log. Regression Test data from: FakeRom | 85.14% |
| Log. Regression Test data from: NEW | 20.25% |
| Log. Regression Test data from: FakeRom and NEW | 19.90% |
| SVM Test data from: FakeRom | 89.43% |
| SVM Test data from: NEW | 21.03% |
| SVM Test data from: FakeRom and NEW | 21.64% |
| Bert Test data from: FakeRom | 92.86% |
| Bert Test data from: NEW | 65.21% |
| Bert Test data from: FakeRom and NEW | 72.21% |
| RoBERTa Test data from: FakeRom | 74.00% |
| RoBERTa Test data from: NEW | 54.94% |
| RoBERTa Test data from: FakeRom and NEW | 59.77% |
ACCURACY - Improved Dataset
| Model | Value |
|---|---|
| Naive Bayes Test data from: FakeRom | 32.57% |
| Naive Bayes Test data from: NEW | 83.33% |
| Naive Bayes Test data from: FakeRom and NEW | 82.92% |
| Log. Regression Test data from: FakeRom | 29.71% |
| Log. Regression Test data from: NEW | 90.41% |
| Log. Regression Test data from: FakeRom and NEW | 90.88% |
| SVM Test data from: FakeRom | 28.57% |
| SVM Test data from: NEW | 94.38% |
| SVM Test data from: FakeRom and NEW | 94.65% |
| Bert Test data from: FakeRom | 99.43% |
| Bert Test data from: NEW | 95.54% |
| Bert Test data from: FakeRom and NEW | 96.53% |
| RoBERTa Test data from: FakeRom | 96.29% |
| RoBERTa Test data from: NEW | 93.80% |
| RoBERTa Test data from: FakeRom and NEW | 94.43% |